Notepad - Logoszféra fórum
üzenetek



hozzászólások

AMD OverDrive™ Utility 3.1.0 (2009-9-20) Update list:
1. Added support for AMD Phenom II X4 965BE CPU
2. Added support for ATI DX11 “Evergreen” graphic cards
3. Added support for additional super IO chip: IT8712
4. Added support for AMD S1g4 and ASB2 socket type CPUs
5. Enhanced the fan speed control and hardware monitoring feature
6. Enhanced AMD Smart Profiles feature
7. Improved the CPU core multiplier settings method to change only the settings of the highest P-state
8. Enhanced the apply settings mechanism for memory timings by only applying the settings that were changed
9. Fixed a bug in AODDriver
10. Fixed the bug that GPU usage cannot be retrieved even with the latest graphic driver

Revision Guide for AMD Family 10h Processors 3.60
[ Szerkesztve ]

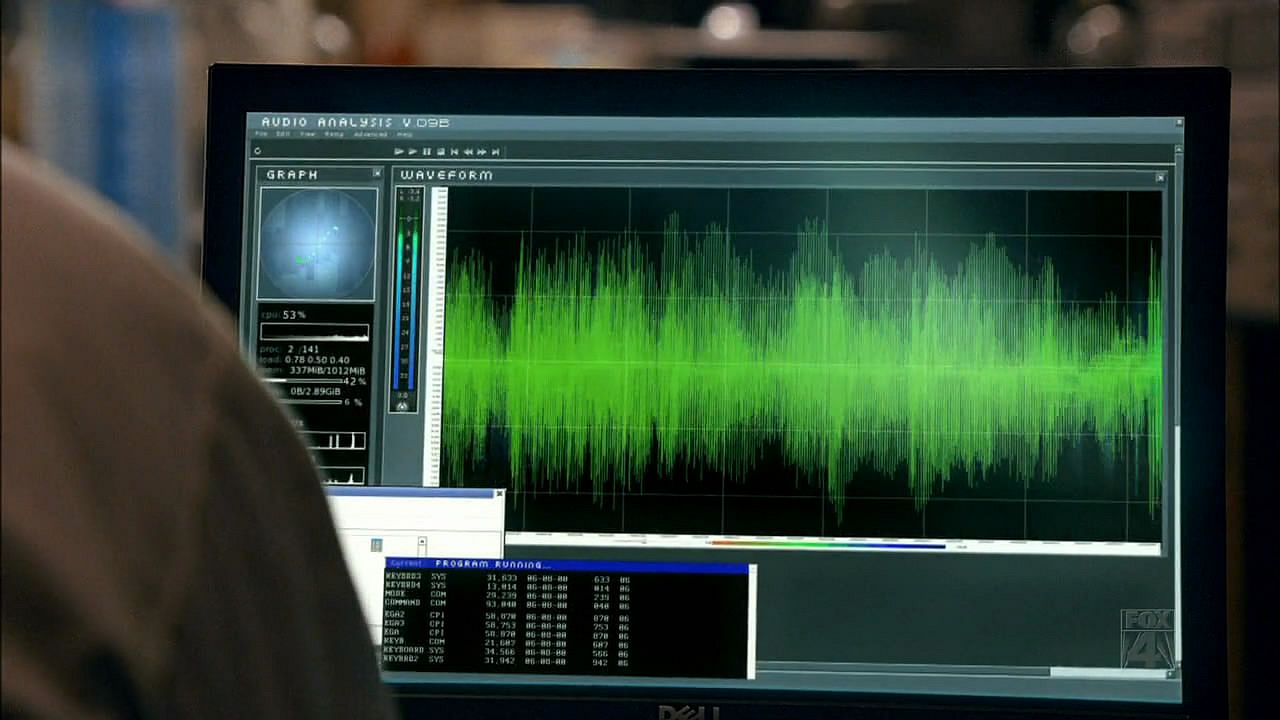
First DirectCompute Benchmark Released
A forum member by the name of Pat has recently released a new benchmark tool for DirectCompute. This tool allows you to benchmark DirectX 11 latest general-purpose computing feature by calculating tons of FFT-like data and some memory transfers. DirectCompute is an application programming interface (API) that takes advantage of the massively parallel processing power of a modern graphics processing unit (GPU) to accelerate PC application performance. Be advised that DirectX 11 and the latest display drivers are required to run this benchmark.
Update: A new version (0.25) is now available.
Download this file in our downloads section.
Dirk Meyer, President and Chief Executive Officer
Nigel Dessau, Senior Vice President and Chief Marketing Officer
Emilio Ghilardi, Senior Vice President and Chief Sales Officer
Rick Bergman, Senior Vice President and General Manager, Products Group
Chekib Akrout, General Manager, Technology Group
Thomas Seifert, Senior Vice President and Chief Financial Officer
Highlights 


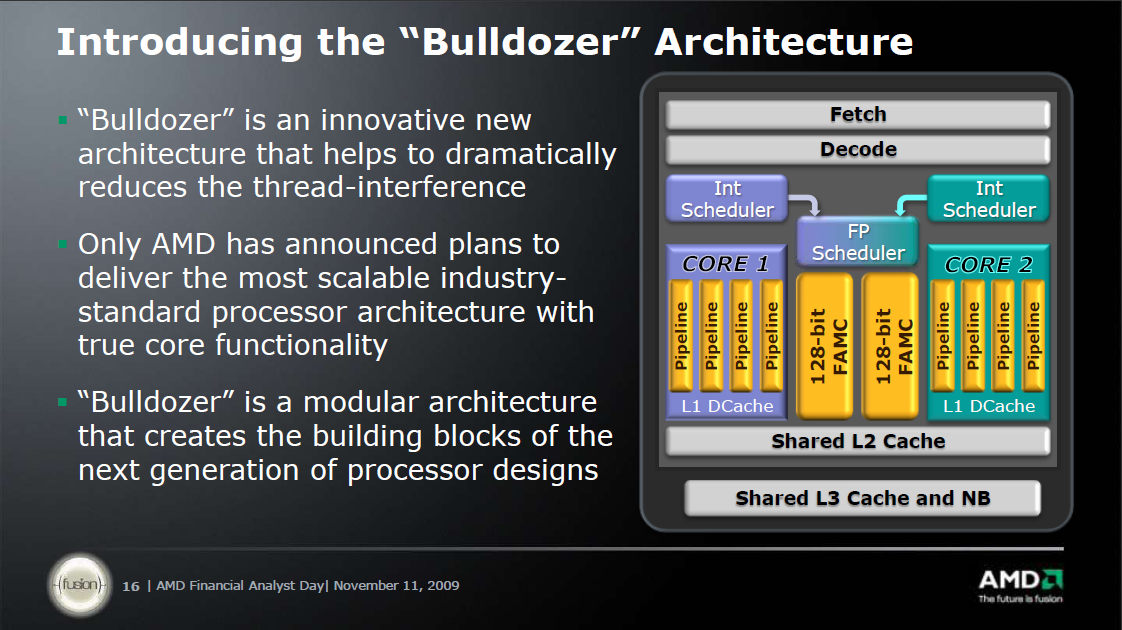
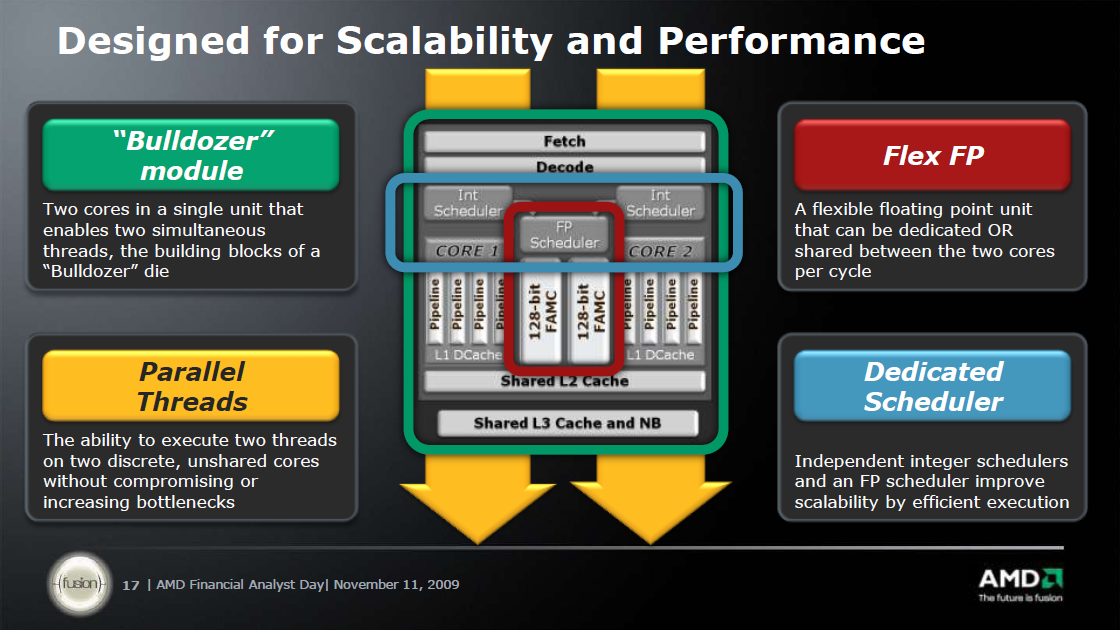






[ Módosította: Thrawn ]



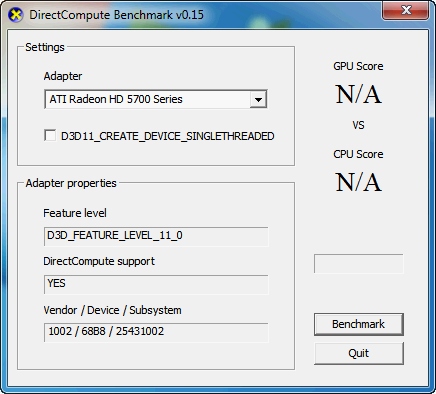
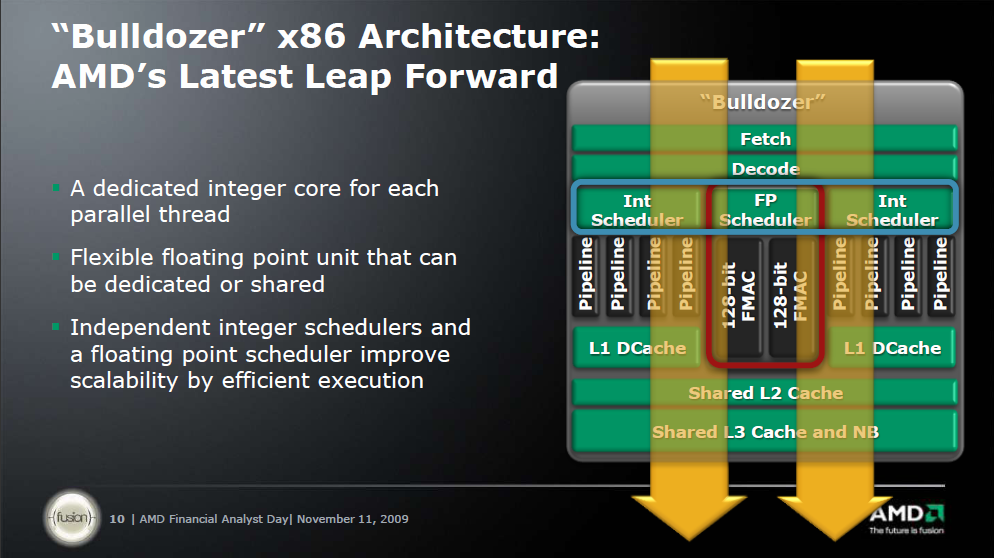
"Interesting to note are the "two tightly linked cores" sharing ressources. The shared FPU (which seems to be capable of 1x256 bit FMAC or 2x128 bit FMAC/FADD/FMUL in any combination per cycle) has been proposed many years ago by Fred Weber (AMD's CTO at that time). He already said, that two cores might share a FPU sitting between them. The whole thing is a CMT capable processor as speculated before. And if we look at core counts of Bulldozer based MPUs we should remember, that 2 such cores are accompanied by 1 FPU and an 8 core Zambezi actually contains 4 of these blocks shown on the Bulldozer slide.
Further the 4 int pipelines per core/cluster aren't further detailed, while for Bobcat they are. In the latter case we see 2 ALU + 1 Store + 1 Load pipes. For BD I still think, that we'll see 2 ALU + 2 AGU (combined Load/Store) pipes. Those "multi mode" AGUs would simply fit better to achieve a higher bandwidth and be more flexible, because the FPU will also make use of these pipes. BTW compared to the combined 48B/cycle L1 bandwidth (could be used e.g. as 48B load bandwidth) of Sandy Bridge we might only see 32B/cycle L1 bandwidth per core but up to 64B/cycle combined L1 bandwidth per FPU (although shared by 2 threads). Finally, nobody knows clock speeds of these processors, so no real comparison is possible right now.
Today rumour site Fudzilla posted some rumoured details of BD, e.g. DDR3-1866 compatibility, 8 MB L3 (for 8 cores) and "APM Boost Technology". A german site even mentioned some mysterious patents pointing into the same direction... Well, given the time frame and filing dates I see both a chance for a simple core level overclocking like Intels Turbo Boost, because this is covered in AMD patents and a chance for a more complex power management on a core component level as described in my second last blog posting."
"Take the current decoders and add a fourth. This would work most of the time but would work better if you add another small buffer between the predecode and decode stages or if you increase the depth of the pick buffer. Then you continue with 4 pipelines to the reorder buffer and down to four dispatch and four ALU/AGU units. You can't break these apart without redesigning the front end decoder and the dispatch units.
The FMAC units are now twice as fast so you really don't need more than two per pair of cores. Besides you can't keep the same ratio while doubling the speed without busting your thermal limits. Even at that, the L1 Data bus is too small. So, you double the width of the L2 cache bus and get your SSE data directly from there. This leaves the existing L1 Data caches to service the Integer units. That increases the data bandwidth by 50%. The current limit is two 128 bit loads per core. If we allow the same for FP then we have six 128 bit loads per core pair. The current limit is two 64 bit saves per core. They could leave this unchanged on the integer side and beef up the FP unit to allow two 128 bit loads, one 128 bit load plus one 128 bit save, or two 128 bit saves. That would give the FP sufficient bandwidth. The front end doesn't really have to be changed since current FP instructions are already sent to another bus. It's a good question of whether each core gets one FMAC all to itself or whether they can intermingle. Either would be possible since threading the FP pipeline would only require extra tags to tell the two threads apart. Two threads would also break some dependencies and partially make up for the extra volume due to tighter pipeline packing and fewer stalls.
Presumably, widening the pipelines to four would give a good boost to Integer performance. I suppose 33% would be the max unless they beef up the decoders but 20% would be enough. I'm guessing they would also change the current behavior of the decoders which now tend to stall when when decoding complex instructions and would probably reduce the decode time on more of the Integer instructions.
The only reason for a complete redesign would be if the architecture extensions can't fit into the thermal limits."
"Each bulldozer module will have 2 integer cores and a shared FPU. When you consider that 80-90% of the work is integer, this is a great way to keep the performance up and reduce power consumption.
For those that said HT was such a great technology because for 5% more die space they get a 10-20% performance bump, the word from our engineers is that adding a second integer core to each bulldozer module is ~5% silicon but nets ~80% performance uplift over a single integer core.
I have been saying for a long time that the HT tradeoff was not worth it, this is why.
You'll see bulldozer-based products with generally the same power and thermals that you see on today's products, but with significantly more throughput."
John Fruehe
Journalist: Rick you mentioned that you will be sampling Bulldozer and Bobcat in 32nm, Fusion products in the first half of 2010. That would suggest that you either have taped out or is close to taping out all those products. Can you give us some sense off where you are in terms of the development on those cores?
Rick Bergman: We don't really give out inner milestones, but we, obviously you know how the semiconductor industry works. You know, June of 2010 is 7 months from now, it takes a few months to build these things so I don't think your comments are off-target at all we are, we're loading up the gun getting ready with our next wave of these fantastic products
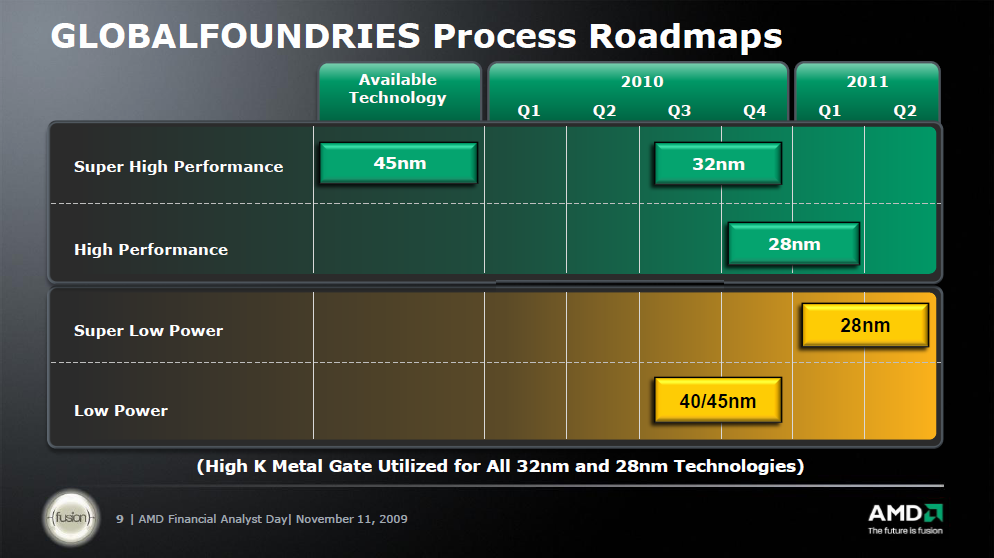
Journalist: You mentioned, I think the roadmap for Global Foundries showed that you had, that they were doing 32nm in the second half of 2010. So how do you actually get those built in the first half?
Dirk Meyer: That was a production question.
Emilio Ghiraldi: That's manufacturing ramp, which is consistent with the...
Journalist: So they are doing the tape-outs now?
Rick Bergman: Oh yeah, absolutely and we have running material, we have material
.
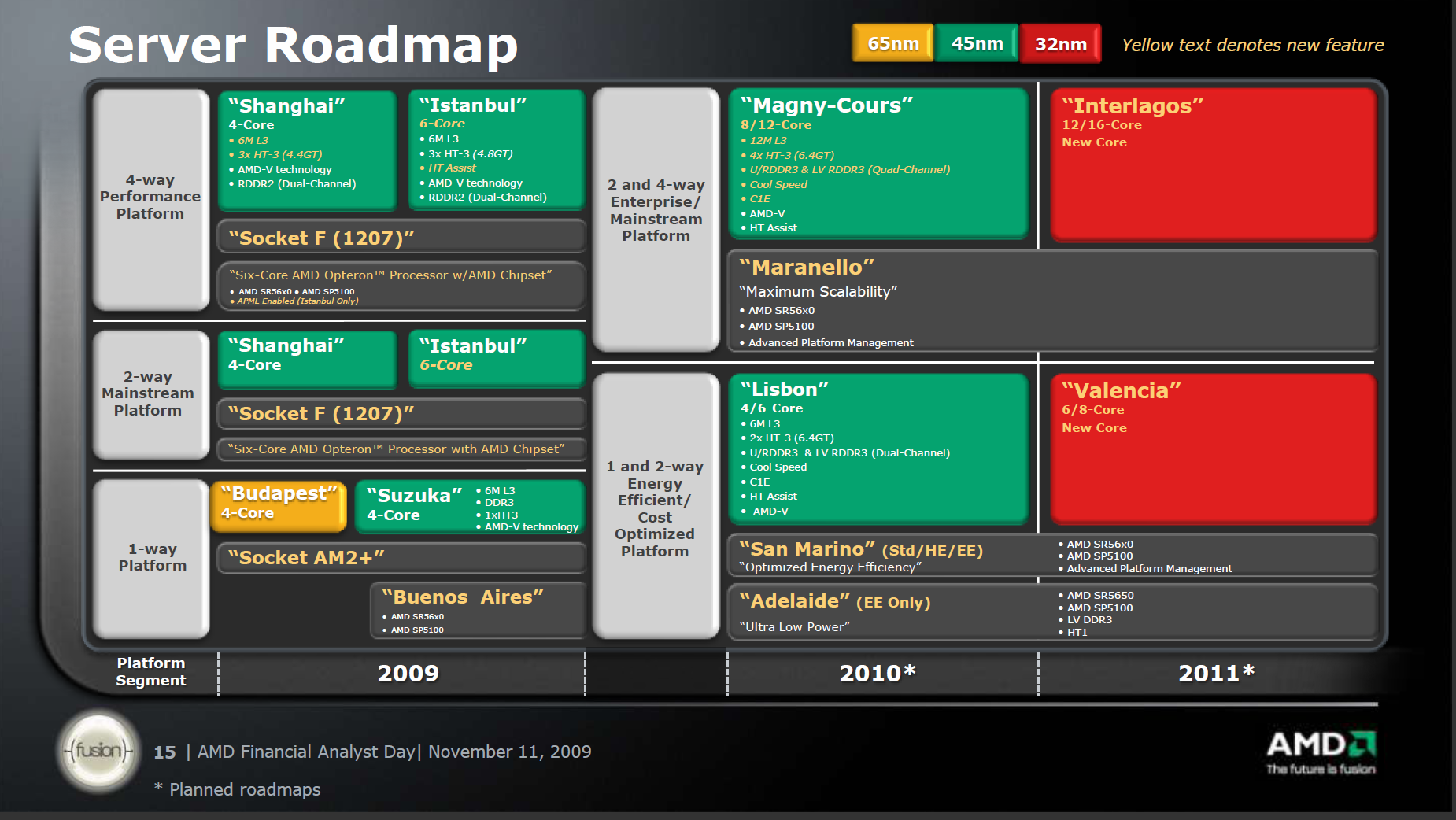
"C32 is a new socket but it is based on the physical 1207 mechanics. This means that all of the tooling and development costs for the socket have been amortized and it is at a low cost. And partners know how to deal with it because they have been laying out with 1207 for years.
We swapped some pin assignments so that we could support DDR-3 and higher capacities of memory, so current DDR-2 parts will not work in the new sockets. We added some keying on the socket to ensure that 1207 fits in 1207 and C32 fits in C32, no mixing. That reduces the test matrix for customers and prevents them from having to support DDR-3 on older parts."
John Fruehe
