
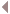

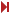
SMT4 lesz-e?
Biztos jó, hogy 1 socketba már 64 mag helyett 192 kerülhet majd. De az igazi nagy durranás a hyperscalereknek ez lenne, ha 1 magát már nem kétszer, hanem 4-szer adhatnának el ügyfeleiknek.
üzenetek
hozzászólások

Petykemano
(veterán)


S_x96x_S
(őstag)
>ABU: Viszont ahhoz, hogy ez a sebesség elérhető legyen, a rendszer óriási tokozást kap,
> mire rengeteg chiplet is ráfér, de ezzel a gyártás is igen drága lesz.
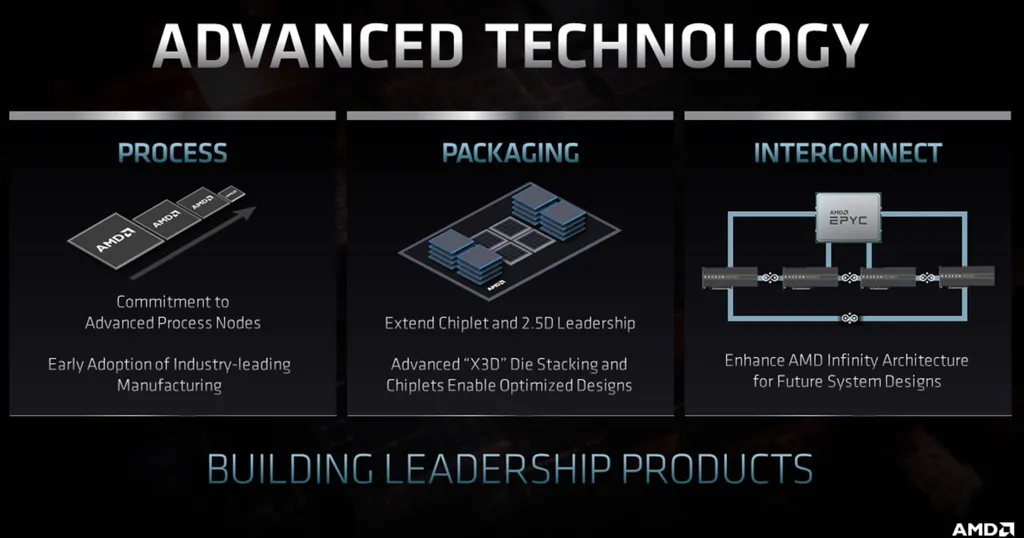
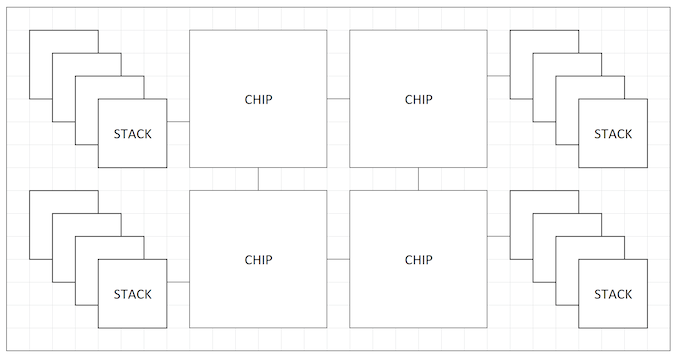
Ha az X3D a ZEN4-el tényleg jön ...
és legalább 2 generációt kiszolgál az új MILAN foglalat
Akkor lehet, hogy a HBM stack-nek ( 32 GB  ) kellhet a hely ..
) kellhet a hely ..
Persze a nagyobb alapterület * emeletes elrendezés még több lehetőséget ad
Ha minden egy tokba kerül - még akkor is minden szűkös lesz

[ Szerkesztve ]

Így, hogy a különféle szoftver licenszeknél már nem a foglalat, hanem a magszám kezd el számítani, már kevésbé van értelme egyutas szerverek felé fordulni. Eddig ugye ebben az volt a poén, hogy prociszám után mentek a licenszek, tehát ugyanannyi volt például a VMWare esetén a licensz ha 16 magvas vagy ha 32 (illetve akár 64) mag volt a prociban. Viszont ha két 16 magos volt, akkor 2 CPU licensz kellett, tehát kétszer annyit fizettél. Ezért lettek az egy utas szerverek egyre népszerűbbek.
Persze aztán a különféle szoftvercégek rájöttek, hogy ez annyira nem jó dolog a pénztárcájuknak, ezért például a VMWare esetén 32 magonként kell CPU licensz, tehát ha 192 magvas, egy utas rendszered lesz, akkor 6 CPU licenszt kell megvegyél.
Ilyen feltételek mellett már nem biztos, hogy olyan hű, de jó ötlet az egy utas szerverek felé fordulni, pláne, ha az adott esetben drágább lesz magszámot is figyelembe véve, mint a két utas megoldások.

Én nem értek hozzá, csak feltételezem, hogy a SMT4 működéséhez jóval több cache (tranzisztor) és beiktatott üres órajel ciklus kell amíg vált az egyes szálak között. így felépítésben komplexebb lenne a CPU és az általánosabb de jobban terhelő feladatokra, ahol mondjuk nem skálázódna csak ~5-10%-ot SMT4 arra használva viszont jóval kisebb hatásfokú, drágább magokat eredményezne, ami nem cél.
#5 Cifu:
Most hogyan viszonyul mondjuk két külön tokozott 64 magos processzor közötti sávszélesség mondjuk egybetokozott 128 magos processzorhoz képest, ez nem lehet valamilyen módon limitáló tényező és indok arra hogy inkább egy utas rendszert építsenek, ha lehet, és tegyük fel olcsóbb is maga a hardver?
[ Szerkesztve ]

Most hogyan viszonyul mondjuk két külön tokozott 64 magos processzor közötti sávszélesség mondjuk egybetokozott 128 magos processzorhoz képest, ez nem lehet valamilyen módon limitáló tényező és indok arra hogy inkább egy utas rendszert építsenek, ha lehet, és tegyük fel olcsóbb is maga a hardver?
Itt a kérdés az, hogy mire szeretnéd használni az adott szervert. Azért zömmel az ilyen sokmagvas gépek már virtuális szerverek hostjaként szolgálnak, mondjuk egy 128 magos szerveren fut két-három fájlszerver, DNS szerver, backupszerver, VoIP szerver és teszem azt egy marék virtuális kliensgép (Távoli eléréshez).
Ilyen esetben picit sem tényező, hogy a két CPU között mennyire fogná vissza a sávszélességet, ez csak ott számít, ahol egy host alól fut sok szálat kihasználó alkalmazás. Ott nyilván még esetleg lehet értelme.

McDuglas
(aktív tag)
Szerintem itt is bejön majd a kis-Epyc-nagy-Epyc kettéválás.
Azok a cégek, akik magszám licenszes vmware-el vagy hasonlóval dolgoznak, lesz a célpontja a kis-Epyc-nek, a nagy-Epyc meg megy az Amazonnak, Google-nek, társainak, ahol saját hypervisort futtatnak.

LGG555
(aktív tag)
Kíváncsi vagyok ez a chiplet dolog hogy fog működni náluk VGA szinten, addig kihúzom a Radeon VII kártyával.
[ Szerkesztve ]
Az Amazon tudomásom szerint nem harapott rá nagy Epyc procikra, 32 magvas verzióikat emlegettek, mikor legutóbb e kapcsán szembe jött velem valami. De ők ugye minél inkább a saját ARM N1 magvas, 7nm-es Graviton2 CPU-ra szeretnének támaszkodni.
Akkor ha jól elmélkedem tovább ennek az egy utas processzornak, nem lehet a 2/4 utas rendszerek a kiváltása direktben célja, ahogy azt a cikk állítja, inkább az ár érzéken "belépő szintet" fedik vele, ahol az ügyfeleknek nem kell, felhasználás tekintetében hátrányos lesz a multi-socket-tel járó skálázhatóság?!



koko52
(veterán)
Hülyéknek még eltudja. Szerencséjükre van még belőle bőven. Viszont ha lejártak a szerződések vagy platform váltás lesz nehéz lesz beadni a főnöknek miért jobb a szarabb, mindezt épp egy intel fizette nyaraláskor. ![;]](/dl/s/v1.gif)
Nálunk egyet kérdez a főnök árajánlatnál: melyik a jobb ár/érték arányban? Na ezt nehéz lenne megmagyarázni...
Jelenleg a szerver proci így néz ki: intel(trabant)-AMD(Ferrari trabant áron)
[ Szerkesztve ]

ttwepinefrin
(tag)
Így van, viszont ameddig van rá kereslet ami az elmúlt években gondolom alábbhagyott, vagy alább fog, addíg elfogja adni.

Szerény véleményem szerint igen, mivel csak akkor lenne létjogosultsága egy ilyen szerverproci-szörnynek, ha olcsóbb, mint két fele ekkora.
Apró probléma, ha például van egy szerver-infrastruktúrád Intel procikkal, VMWare virtuális hostokkal, akkor abba nem tudod beilleszteni az AMD szervert tudomásom szerint. A VMWare előnye az lenne, hogy leállítás nélkül tudnád a VM-eket mozgatni a szerver hostok között például, aminek előnyét aligha kell ecsetelni. Na a fentiek alapján sejthető, hogy mennyire lelkesedne bárki is az AMD szerverre való átállásért egy ilyen környezetben...
Szóval itt nem arról van szó, hogy mindenki hülye, aki Intelt vesz, hanem arról (is), hogy az, hogy az AMD a szerverpiacon kvázi láthatatlan volt az EPYC előtti időkben...
dokanin
(aktív tag)
Azért az elég durva, hogy lehet hostot cserlélni leállítás nélkül. Nem gondoltam volna, hogy ilyen lehetséges technikailag.
És ez AMD alatt miért nem megy?

Ennek a procinak én mérnökirodákban látom a helyét. CFD, FEA stb. Vagy kisebb stúdiók, akik nem akarnak rohadt nagy farmra beruházni, mert az nem térülne meg De egy ilyen alapú cucc elfér a szekrényben, és egész normálisan tudják terhelni munkával. Vágás, render, crash stb.
#20 dokanin Szerintem ez oda-vissza igaz, vagyis csak irgalmatlan költségekkel, bevételkieséssel lehet az adott rendszert más gyártó termékére átállítani. És annak az időigénye, tesztigénye, supportigénye is súlyos tétel.
[ Szerkesztve ]
Azért az elég durva, hogy lehet hostot cserlélni leállítás nélkül. Nem gondoltam volna, hogy ilyen lehetséges technikailag.
vMotion-nak hívják a VMWare esetén a Live Migration-t, de létezik Hyper-V alatt is (ahhoz nem értek annyira, no nem mintha VMWare esetén olyan hú, de penge lennék  ).
).
És ez AMD alatt miért nem megy?
AMD alatt is megy, amennyiben AMD alapú szervereken (clusteren) fut a VMWare vSphere. A probléma az, hogy nem tudsz beilleszteni egy AMD alapú clusterbe Intel, mígy Intel alapú clusterbe AMD procis szervert. Tehát Intel alap esetén csak Intel alapon tudod bővíteni, míg AMD alapon csak AMD szerverrel tudsz bővíteni.
Alaphangon hogy a rendszer gördülékeny legyen, a szerver hostoknak azonos CPU-val, de legalábbis azonos családba tartozó CPU-val kell bírjanak. Így lehet biztosítani, hogy a VM minden szerveren azonos feltételek mellett (azonos utasításkészleten) fusson.
Az egy ideje elérhető, hogy újabb szervereket tudj beilleszteni, ezt hívják Enhanced vMotion-nak. Ennek az első verziói alapvetően elrejtették az új proci új utasításkészletét a VM-ek elől, azt hazudva, hogy a clusterben lévő legrégebbi CPUID-t vették alapul.
Magyarul van egy clustered Ivy Bridge-EP alapon, de be szeretnél illeszteni egy Haswell-EP procis szervert. Ilyenkor az EVM azt csinálja, hogy az ESXi felett a VM-ek Ivy Bridge-EP alapú hostot látnak, tehát "lebutítja" az újabb szervert a régiek szintjére. Ez némileg favágó módszer, de ha fejleszteni kell a cluster méretét, még mindig életképesebb ez a megoldás, minthogy régi szerverekből próbálsz vásárolni. Hátránya, hogy az új szerverek is a clusternek megfelelő régebbi CPUID (és utasításkészlet) lesz csak elérhető.
A következő lépcső a Per-VM alapú EVM, ilyenkor a VM-k létrehozásakor meghatározod, hogy milyen hoston futtatod, és ez korlátozza be utána, ez a VMWare esetén a 6.7-től jelent meg. A fenti példával élve a clusterbe beillesztett Haswell vagy Skylake alapú szerverre továbbra is át lehet migrálni a régebbi szervereken futtatott VM-eket gond nélkül, de az új szerveren létre tudsz hozni már olyan VM-eket, amik kihasználják az új utasításkészleteket. A Per-VM alapú EVM hátránya, hogy a clusteren belül már nem tudod teljesen szabadon migrálni a VM-eket bármelyik szerverről bármelyikre, de viszont azt meg tudod oldani vele, hogy rugalmasan mozgas és hozz létre VM-eket, így például egy ritkábban használt VM-et (mondjuk pl. VoIP, ami relatíve ritkábban szokott cserélve lenni) akár úgy is viheted folyamatosan tovább, hogy alatta közben lecseréled a teljes infrastruktúrát.
[ Szerkesztve ]
Ennek a procinak én mérnökirodákban látom a helyét. CFD, FEA stb. Vagy kisebb stúdiók, akik nem akarnak rohadt nagy farmra beruházni, mert az nem térülne meg De egy ilyen alapú cucc elfér a szekrényben, és egész normálisan tudják terhelni munkával. Vágás, render, crash stb.
Dunno, oda inkább Threadripper-t tartanék reálisnak az AMD eddigi felállásából. Ráadásul a mérnökök főleg CAD alapú megoldásokkal dolgoznak, ott pedig (amennyire én követem az eseményeket) továbbra is fontosabb az IPC, mint a több mag.
dokanin
(aktív tag)
Ha jól értem, akkor a vm-en futó szolgáltatás gyakorlatilag le sem áll miközben lecserélem a hostot pl egy többmagosra?
dokanin
(aktív tag)
Közben elolvastam a linket.
Durva. Sosem gondoltam volna, hogy ilyet lehet.
A vMotion esetén mozgathatod a működő, dolgozó VM-et mondjuk egy 16 magos szerverről egy 24 magosra, de mindkettőnek azonos családba kell tartoznia (pl. Skylake-EP).
A hostot akár újabbra is cserélheted már, tehát Skylake-SP helyett Cascade Lake-SP procis szerverekre, ehhez kell az EVM.
És igen, ez azt jelenti, hogy a VM közben fut, dolgozik, végrehajt, semmi vagy minimális lassulással...
[ Szerkesztve ]

Dolpa
(tag)
Semmi gond nincs azzal, ha keverve vannak a clusted node-ok.
Van erre már régóta működő megoldás az EVC, de lehet ugyanabban a clusterben AMD és Intel gép is. Nyilván a HA csoportokat úgy kell beállítani, hogy csoporton belül azonos CPU család legyen.


zetor2000
(senior tag)
Hát, ha per mag 2GHz, az 64 magnál elég dulva tempó tud lenni. De ha jól értem a czikket, akkor ez a legócsárébb szr lesz, a belépő szint 64 mag  Szóval ilyet csak a csórók fognak venni
Szóval ilyet csak a csórók fognak venni 

GIstvan83
(csendes tag)
Cifu, ez nem teljesen így van. Én igaz kicsit ma már réginek számító, de egy 10 magos xeonnal cad munkákat csinálok. Sajnos az elmondható, hog mikor egy 3d modellt, felületmodellt tervezel, a munka javareszt nem többszálúsítható. De a cad munka nem csak ennyiből áll. Van amikor stress testre, cfd analizisre van szükség, ez azonos programon belül, ahogy a remder is kihasználja mind a 20 szálat. Emellett még más jellegű gázdinamikai programot is használok, szintén többszálúsítható. Nem mondom, kellaz ipc es a sok mag közt a ballansz. De egyik a másik nélkül nem érvényesül. De reális keretek közt inkább a több mag. Van perszebolyan, mikor jól esne, hogy egy klikk ne 3 percig tartson egy combos felüetmodellnél, hanem 2 percig. De ilyenkor úgyis közbe böngészek. De azért a gázdinamikai szoftverben ha 2 nap helyett 4 óra alatt fut le a szimulació, na az mar nem mindegy. Ezért is vettem annó CADre 10 magos xenont. Es igazaból nem is tudom merre fejlesszek, lehet csak low budget lesz, dual socket, dupla rammal, 2x10 maggal a szimulációs részek miatt. Igazából az én munkámnál ez az egyszálas teljesítmény élhető. Úgyis gondolkozol közben, nem számít annyira sarkosan. De azért 64 akár ilyen kehes maggal már álomszerű lenne. Pl egyszerűbb gázdinamikai programok anno a c2dhez képest nem napi 1 2 futtatásra, hanem úgymond félig meddig realtime menne, azaz mire lefuttatom egy verziót és kielemzem, már fut alatta a másik. És nem fűt órákon át, miközben malmozom, mint egy kazán 🙂
S_x96x_S
(őstag)
> Az órajel meg marad 2 GHz?
ahogy beleférnek a power keretbe ..
de az "AMD EPYC 7F Rome Processors " procik már most is > 3Ghz
- EPYC 7F32 : 8c /16t base: 3.70 Max: 3.90
- EPYC 7F72: 24 c/ 48t base=3.20 Max=3.70
https://www.anandtech.com/show/15715/amds-new-epyc-7f52-reviewed-the-f-is-for-frequency
"Dunno, oda inkább Threadripper-t tartanék reálisnak az AMD eddigi felállásából. Ráadásul a mérnökök főleg CAD alapú megoldásokkal dolgoznak, ott pedig (amennyire én követem az eseményeket) továbbra is fontosabb az IPC, mint a több mag."
A CAD-es mérnkök igen, a CFD-s, CAE-s emberek meg rohadtul nem. CAD-re valóban egyetlen szál kell ma is, de FEA, CFD területen meg nagyon jól jön a minél több mag. Még a webes SimsCale esetében is tudsz magszámot meghatározni, mennyin fusson a számítás. Komolyabb cluster helyett egy CPU is eég lehet a rengeteg magjával egy-egy számításhoz.

opr
(veterán)
Ebben a helyzetben a helydben lehet kivarnam inkabb az uj threadrippert, az uj zennel, abszolut arany kozeputnak tunik. Persze csak ha eleg az a ~256gb max memoria, amit valoszinuleg tamogatni fog.
[ Szerkesztve ]

ukornel
(aktív tag)
Néhány bővített tőmondatban el tudnád magyarázni, miért nem többszálúsítható a CAD?
(Csak hogy egy laikus is értse, nem CAD-eztem soha, csak FEM, MCS)
GIstvan83
(csendes tag)
Lepasszolom a kérdést, de siemens supporton (nx, solidedge) és 3ds (catia, sw), autocad, stb. azt írják, hogy a műveletek nem párhuzamosíthatóak. Kivéve a fluid, más szimulációs és render részeket.
Mert a logikája nem alkalmas párhuzamos felépítésre. Hogy épül fel egy test, az hogy változik, mikor marad anyag, mikor tűnik el, ritkán van elágazás a modellekben. meg lehet oldani rakat boolean operátorral is a modellezést, de akkor is kevés elemre referál, és mindig kell neki a teljes testmodell állapota a következő lépés számításához.

sok esetben mar igeny van akkora magszamu VM-ek futtatasara, ami nem megoldhato egyetlen socketben (legalabbis Intelen, mittomen fizikai 32 mag), ott mar nagyon szamithat, hogy ket socket vagy egy. a ket socket-et osszekoto QPI/UPI (Intel) tobbfele terheles eseten is nagyobb teljesitmeny-csokkenest okoz, mint a socket-en beluli CCX-ek v CCD-k kozotti kommunikacio (AMD). legtobbszor ezt annyival letudjak, hogy a VM-hez rendelendo fizikai magszam megall az egy socket-ben levo magok szamaval es kikotik, hogy NUMA hataron nem nyulhat at a VM.
tehat tipikus eset, amikor futtatsz egy bazinagy VM-et (vagy rengeteg szalat kezelo applikaciot) es AMD-Intel osszevetesben valamekkora magszamig az Intel gyorsabb, de amikor mar masik socket-bol is kene az eroforras, az Intel skalazodasa rosszabb lesz, mig az AMD gyakorlatilag linearisan megy tovabb.
ez termeszetesen csak akkor igaz, ha a VM nem NUMA-aware (nincs felkeszitve/optimalizalva NUMA eroforrasok kezelesere).
Es itt jon be az AMD BIOS-okban beallithato NPS (NUMA Per Socket) szerepe, hogy ki lehessen facsarni a legjobb teljesitmenyt a procibol, ha a szoftver kepes ra. ha meg nem, akkor inkabb legyen a belso architektura elrejtve, mert csak csokkenti a teljesitmenyt (pl nem a futtato CCX-hez/CCD-hez legkozelebbi memoriavezerlo hasznalata, stb).
[ Szerkesztve ]
ukornel
(aktív tag)
Aha, köszi a választ, így valamivel világosabb.
Közben kicsit keresgettem a neten a témában, és az jött le, hogy elvileg nem kizárt a CAD műveletek minél szélesebb körű párhuzamosítása, de a gond az, hogy a test .dwg fájlban tárolt "adatbázisának" megváltoztatása szóba sem jöhet, lévén hogy kvázi iparági szabvánnyá vált. Az ilyen irányú a kutatások valószínűleg soha nem térülnének meg.
Vagy valami ilyesmi.
A DWG már rég nem iparági szabvány, pláne nem 3D modellekhez. De egy 3D modellt a logikája alapján sem tudsz hogy felszeletelni párhuzamos számításra.
Csak épp nem csak annyi van, hogy simán kihúzol valamit. És random előre hogy tudod eldönteni amikor a programot kell írnod, hogy mennyire akarnak majd teljesen módosíthatatlan sketcheket használni, hogy párhuzamos lehessen a számítás? A sketch is és minden egyéb a matematikailag egzakt elemekre épül, amiket minden lépésnél meg kell keresni, megvan, eltűnik, mikor van rá hivatkozva stb. Sokkal több meló párhuzamosítani, minden lépést vizsgálva, szétosztva, mint hagyni egyenesen végig futni.
Kiosztást utoljára 2005 körül láttam, hogy megfogta a gyenge gépet, akkor sem azért, mert a művelet maga bonyolult volt.
