VMware és GlusterFS
Egy beszélgetéssel indult, hogy hogyan lehetne több gépre vSphere-t húzni közös háttértárral. Egy teszt lett belőle... – írta: frescho, 9 éve
A rendszer felépítése
Koncepció
A kiválasztott GlusterFS egy nagyon jól, akár több petabájtig skálázható file rendszer. A clusterben lévő gépek által kiajánlott tároló egységeket, brickeket fogjuk össze volume-okká. Amikor létrehozzuk ezeket, akkor lehet megadni, hogy az adatot hogyan osszuk el a brickek között. A merevlemezeknél meglévő raidhez hasonlóan lehet egy volume:
- elosztott: raid0 szerűen stripe vagy file alapú
- tükrözött: raid1 akár több brickre
- tükrözött és elosztott: raid10
- meghatározott hibatűréssel elosztott: raid 5 és 6 szerű
Ez csak az alap, ugyanis képes snapshotokat kezelni, sérülés esetén helyreállítani magát, illetve újrabalanszolni a tárolást. A cikk nem a GlusterFSről szól, ezért akit jobban érdekel, annak ajánlom, hogy innen induljon el.
A linux alapú rendszerektől eltérően az ESXi-n nem lehet natívan GlusterFS-t futtani, ezért egy kis virtuális gépet (storage VM) hoztam létre minden hoston. Ezen a ponton több lehetőség is van a VM és a host összekötésére. Lehetett volna iSCSI, de én inkább az NFS-re szavaztam és a gluster beépített NFS szerverét használtam.
Elvileg ezzel valamivel lassabb, de arra számítottam, hogy a limitet más jelenti, ahogy látni fogjátok ez be is jött. A vSphere clustert egy egyszerű trükkel csaptam be, hogy egyetlen tárolónak láthassa az elosztott rendszert. Az ötletet valahol olvastam, megpróbáltam lerajzolni, hogy érhetőbb legyen. Az ábrán csak két host van, de többel (3-4) is tökéletesen működött.
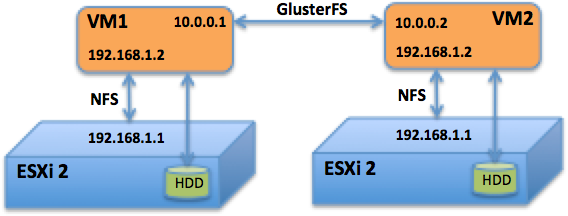
Minden hoston két virtual switchet hoztam létre. Az első a külső forgalomért felelt, ahol minden host és a tárolásért felelős storage VM-ek is külön IP-t kaptak. Ezen zajlott a GlusterFS cluster, vCenter és a többi VM kommunikációja is, amiket VLAN-ok segítségével szeparáltam el. A második vswitch-en a storage VM és a hostja kommunikált. Mivel a második switchre kötött hálózati csatolóknál mindenhol ugyanazokat az IP-ket (192.168.1.1 és .2) vettem fel, ezért a cluster konfigurációnál egyetlen közös tárolónak látta a gluster clustert a vSphere.
Telepítés
Mivel kísérletről van szó, a gépeket kézzel telepítettem, de mindegyiket azonos módon egy script segítségével. Használhattam volna kickstartot/puppetet is, de nem tettem. A gépek mind a négy merevlemeze egyetlen raid 10 tömbbe került, az 1 GB cache write back üzemmódba lett állítva. A hyper threading és az energiagazdálkodás is engedélyezve volt a tesztek alatt. Csak két Gigabites hálózati interfészt volt bekötve a négyből, ami már első ránézésre is szűk keresztmetszetet jelent a merevlemezekhez képest, ezért is elégedtem meg az NFS-el.
A hardverre CentOS 6.6-ot és Windows 7 Pro-t telepítettem közvetlenül és ESXi 5.5-re is. A tisztán hardveres referencia méréseket megismételtem nagy VM-ek segítségével, ahol a host összes erőforrását megkapta a virtuális gép. Ezzel a módszerrel elég jól fel lehet mérni, hogy mekkora veszteséget jelent a virtualizáció. Ennek az eredményeit láthattátok a következő oldalon.
A GlusterFS-t futtató gépek 8GB memóriát és négy CPU magot kaptak. Mivel négy gépre tudtam rátenni a kezem, ezért kipróbáltam két és négy géppel is a GlusterFS-t. Kicsit megpróbáltam optimalizálni, játszottam MTU-val és más beállításokkal. A teszt eredményeknél a megnevezések az alábbi beállításokat takarják:
physical: Gondolom egyértelmű, a fizikai vason futtatott teszt, mint referencia
virtual: Az adott hoston futtatott egy szem VM, ami megkap minden erőforrást. Ezzel próbáltam mérni, hogy a virtualizációval mekkora teljesítményt veszítünk.
2 brick, same: Két bricket használtam a négyből, az adat GlusterFS-el van tükrözve két host között. A mérést végző VM olyan gépen fut, ahol az egyik brick van.
2 bricks, diff: Hasonló az előzőhöz, csak itt a gluster storage VM hálózaton keresztül szolgálja ki az ESXi-t, a brickek másik hoston futnak.
2 bricks, opt: 2 bricks, same optimalizációja. A paramétereket lásd az oldal végén
4 bricks: 4 gluster brick, az adat raid10 szerűen egy pár között szétosztva és mirrorozva a másik hasonló párra.
Beállítások
Gluster:
gluster volume set vol1 diagnostics.brick-log-level WARNING
gluster volume set vol1 diagnostics.client-log-level WARNING
gluster volume set vol1 nfs.enable-ino32 on
gluster volume set vol1 nfs.addr-namelookup off
gluster volume set vol1 performance.cache-max-file-size 2MB
gluster volume set vol1 performance.cache-refresh-timeout 4
gluster volume set vol1 performance.cache-size 256MB
gluster volume set vol1 performance.write-behind-window-size 4MB
gluster volume set vol1 performance.io-thread-count 32
gluster volume set vol1 nfs.disable off
gluster volume set vol1 nfs.volume-access read-write
Optimalizáció:
vSwitch, ESXi és storage VM esetén is MTU=9000. A külső kommunikációt bonyolító vSwitchen engedélyeztem az LACP-t, a forgalom elosztása forrás és cél MAC cím hash alapján történt. Persze ez fölösleges két gép esetén, de nem hagytam ki ezt a lehetőséget sem. Több brick esetén javíthat a sebességen.
echo deadline > /sys/block/sda/queue/scheduler
mount -o remount,noatime /brick
echo 219136 > /proc/sys/net/core/rmem_default
echo 219136 > /proc/sys/net/core/rmem_max
echo 219136 > /proc/sys/net/core/wmem_max
echo 219136 > /proc/sys/net/core/wmem_default
A cikk még nem ért véget, kérlek, lapozz!

Előzmények
-
Alsóház - Celeronok és Kabini
Kis méretű, alacsony fogyasztású lapot kerestem új projektekhez. Az alsó házból próbáltam válogatni: J1900, A4-5000, 1037U.
-
SaltStack#2: Központosított telepítések
Három részes sorozatom második részében az "állapotokkal" ismerkedünk meg, és elkezdünk összerakni egy webkiszolgálóhoz szükséges alap rendszert.
-
Phenom II X6 - érdemes váltani?
Közel öt éve jelentek meg az első X6-ok. A kérdés nem az, hogy elavultak-e, hanem az, hogy mennyire. Érdemes váltani?
