


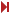

Kód, még jobban kiegyenesítve, mostmár a teljes mártix egy ciklus, egy-egy sora helyett. AMD-n 2.3 IPC.
@@2ND_STEP:
neg ebp
mov esi,[esp+__MTX]
sub esp,20h
mov ebx,ebp
mov edx,00FFFFFFh
mov ecx,ebp
@zeroinrow:
bt dword ptr [edi+ebx],01h
setc ah
mov al,[edi+ecx]
and al,01h
cmp edx,[esi]
adc al,ah
jnz @nx2col
xor edx,edx
add esp,20h
add edx,[esi]
jz @@DECIDE_NEXT_STEP
pushad
@nx2col:
add cl,01h
lea esi,[esi+04h]
cmovz ecx,ebp
adc ebx,00h
jnz @zeroinrow
Most szembesültem először azzal igazán, hogy az AMD féle generális "single cycle execution" + a 2 loads/cycle felépítésre megírt program Intel-en (Core2) fájóan lassabb, mint AMD-n. No ekkor mit lehet csinálni? Az általános gyors vagy AMD-specializált (de az általánosan elterjedt CPU-kon lassabb) megoldás a jobb?
[ Szerkesztve ]
