



Ez eleg lassunak tunik, legalabbis en tobbre szamitottam. A sima RTX2080 csinal az SD1.5-el olyan 9 it/s korul. Nalam a vae-ft-mse-840000-ema-pruned.safetensort van a VAE-ra hasznalva es ahogy nezem nalad azert is sir hogy xformers nincs, nalam az is megy. Az alap SD1.5-bol van egy TensorRT verziom is, az igy fut az RTX2080-on:

A nem konvertalt "alap" ahogy fentebb reszletezve pedig igy:
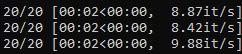
Probald meg a Fooocus-t. Ott csak ezt a zip-et kell letolteni, kicsomagolni es utanna run.bat [link] letolt maganak mindent ami kell beleertve a model/weight file-okat igy eltart egy darabig az elso inditas (foleg a 6GB+ JuggernautXLv8 letoltese miatt) de utanna szepen megy minden. Ha valtoztatsz a Preset-en (az Advanced alatt, itt allitsd 1024x1024-re a meretet is) akkor letolt mas modelleket is [link] de ezt latod a konzolban hogy miert "nem tortenik semmi azonnal". Az RTX2080 itt 1.83 it/s amit tud. Ez a specs amit detekal:
Total VRAM 8192 MB, total RAM 32714 MB
Set vram state to: NORMAL_VRAM
Always offload VRAM
Device: cuda:0 NVIDIA GeForce RTX 2080 : native
VAE dtype: torch.float32
Using pytorch cross attention
Refiner unloaded.
Running on local URL: http://0.0.0.0:7865
model_type EPS
UNet ADM Dimension 2816
Kicancsi lennek mit ir nalad a VAE dtype-ra, itt F32, az RTX4090-nel BF16.






 Generalsz kepet a sima model es VAE kombinacioval, kapsz egy it/s erteket. Aztan generalsz ugyanolyan felbontasu kepet az aktivalt TRT UNet-el es megint kapsz egy it/s ertket. Az a 3 -> 8 az nagy ugras. En csak a 4090-el probaltam par honapja szinten az SD1.5 model konvertalasaval es ott csak olyan 65-75% pluszt hoz igy nem sok ertelme van. Az a kartya mar az SDXL 1024x1024 kepeket is 3-4mp alatt generalja 30 lepessel, nincs sok ertelme az 512x512 vagy 768x768 felbontasu kepeket gyorsitani, foleg mert azoknal mar kell mas is (hiresfix vagy mas upscaler, inpainting stb.) es ott sok a limitacio es a model swapping igy az amit nyersz elveszik a komplett processzben. Nalad viszont egyertelmuen van ertelme ha 2.5x gyorsabban general.
Generalsz kepet a sima model es VAE kombinacioval, kapsz egy it/s erteket. Aztan generalsz ugyanolyan felbontasu kepet az aktivalt TRT UNet-el es megint kapsz egy it/s ertket. Az a 3 -> 8 az nagy ugras. En csak a 4090-el probaltam par honapja szinten az SD1.5 model konvertalasaval es ott csak olyan 65-75% pluszt hoz igy nem sok ertelme van. Az a kartya mar az SDXL 1024x1024 kepeket is 3-4mp alatt generalja 30 lepessel, nincs sok ertelme az 512x512 vagy 768x768 felbontasu kepeket gyorsitani, foleg mert azoknal mar kell mas is (hiresfix vagy mas upscaler, inpainting stb.) es ott sok a limitacio es a model swapping igy az amit nyersz elveszik a komplett processzben. Nalad viszont egyertelmuen van ertelme ha 2.5x gyorsabban general.
