
pdf mindig is muszaj megoldas volt mert ha nem volt masban akkor azt kellett szeretni. ma mar talan megoldhatobb lenne valami konverzioval. na meg ez a pdf kepes dolog is olyan hogy odairjak, aztan mikor megveszed es szeretned hasznalni akkor kiderul hogy a gyakorlatban nem igazan jo sehogy sem (2009-rol es sony-rol van szo).
meta adatok nekem eleg egyszeruek, volt valami info fajl minden doksi mellett (95%-ban rtf-ben tartottam mindent).
ebben kb 4 adat volt, kategoria, szerzo, cim es fajl nev (sima szoveges fajl). ha nagyon nekiduraltam magam ekezetesitettem. a fajl neve eleve hosszu volt, szerzo es cim egyben.
ebbol az infobol legeneraltam neki egy sajat progival az o media.xml-jet. voltak benne csavarok mire felderitettem a strukturajat.
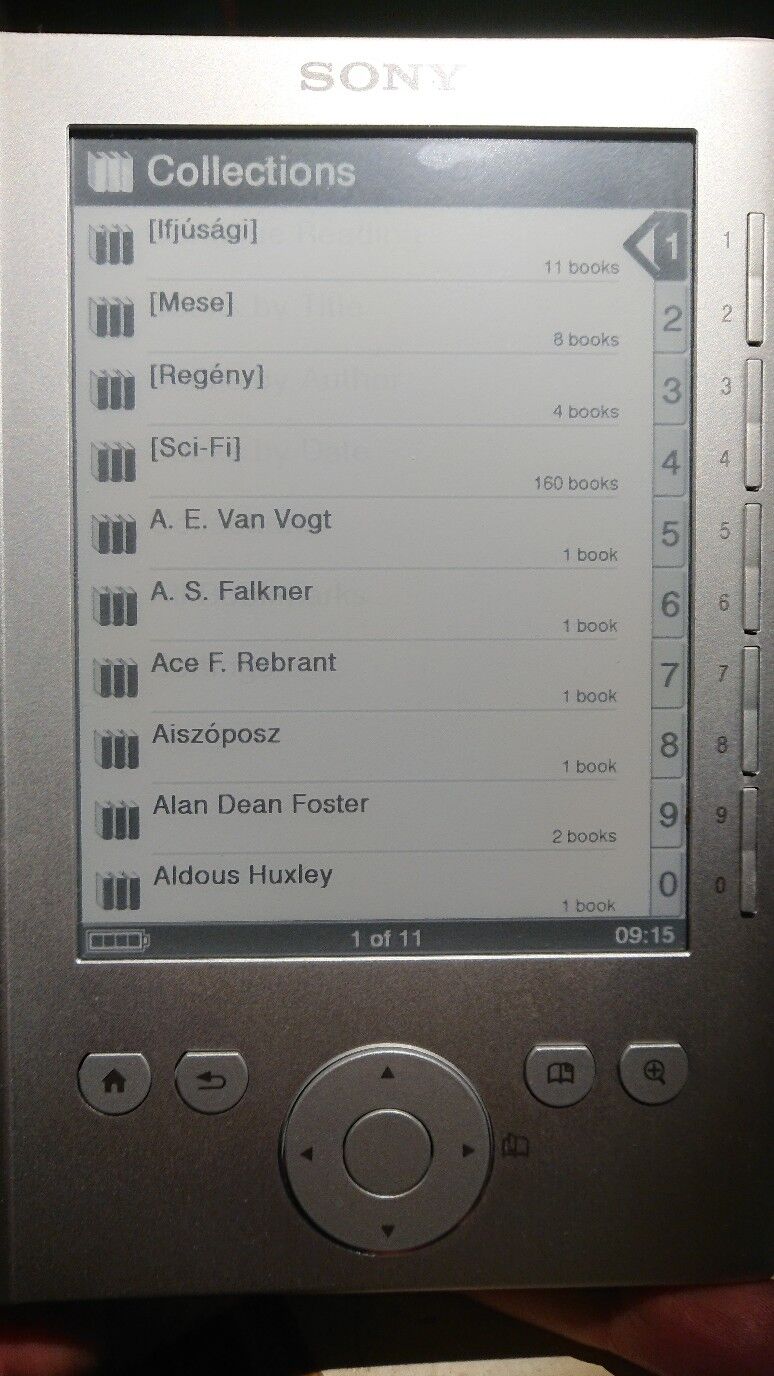
a fo kepernyojen hivatalbol van 4 kategoria:
-books by title
-books by author
-books by date (ez lenyegtelen)
-collections.
ha a media.xml-t eloallitottam neki akkor ezeket a focsoportokat tudta kezelni.
a collections-ban meg szepen szet voltak valogatva a kategoriakba rendezett konyvek.
mivel a ketagoriakat en hataroztam meg igy mint egy konyvtarszerkezet ott volt minden pl "[SciFi] 160 books". ugyan ezen a szinten alatt a szerzok: "Aldous Huxley, 1book"
nem mondom, hogy tokeletes de eleg jol tudtam kezelni es ami a fo hogy ezt nem a tetu lassu procijan kellett kialakitanom (vagy valami kezelhetetlen csodaprogival mint pl a hozza adott sajatja vagy a calibre ami annyi szemetet volt kepes gyartani hogy hamar kaosz lett fajl szinten). annyi jo lett volna, hogy tudjam torolni a fajlt magan az olvason de azt nem tudta (azt meg en nem tom van e olyan ami tud ilyeneket).